
I got a query about a curious incident of two recursive calls, both causing a stack overflow. But when the calls are reversed, one of them succeeds. Read on to find out how the case unfolds.
Ever so often, I get queries from people who are under the misapprehension that I know everything about Java. David Taylor from San José State University sent me this puzzler that he got from his colleague Ben Reed.
import java.util.Arrays;
public class StackOverflowMystery {
static int[] memo;
static int fib(int i) {
if (i < 2) {return 1;}
if (memo[i] != -1) {return memo[i];}
memo[i] = (fib(i - 2) + fib(i - 1)) % Short.MAX_VALUE;
return memo[i];
}
static void doFib(int i) {
try {
memo = new int[i + 1];
Arrays.fill(memo, -1);
System.out.print("fib: " + fib(i));
} catch (StackOverflowError e) {
System.out.println("fib: stack overflow at " + i);
}
}
static int fib2(int i) {
if (i < 2) {return 1;}
if (memo[i - 1] == -1) {memo[i - 1] = fib2(i - 1);}
if (memo[i - 2] == -1) {memo[i - 2] = fib2(i - 2);}
memo[i] = (memo[i - 1] + memo[i - 2]) % Short.MAX_VALUE;
return memo[i];
}
static void doFib2(int i) {
try {
memo = new int[i + 1];
Arrays.fill(memo, -1);
System.out.print("fib2: " + fib2(i));
} catch (StackOverflowError e) {
System.out.println("fib2: stack overflow at " + i);
}
}
public static void main(String[] args) {
int n = args.length < 1 ? 20_000 : Integer.parseInt(args[1]);
doFib(n);
doFib2(n);
System.out.println("====> reversing the order");
doFib2(n);
doFib(n);
}
}
Never mind that there is a much better algorithm for computing Fibonacci numbers. The Fibonacci numbers aren't the point. They just provide an example of an algorithm with high stack depth.
Go ahead, compile and run it. There are two versions of computing the Fibonacci sequence with memoization (i.e., remembering previously computed values). A bit of background. Without memoization, computing
fib(n) = n < 2 ? 1 : fib(n - 2) + fib(n - 1)
is really bad. You keep recomputing the same values. For example:
fib(10) -> fib(8) -> fib(6) -> ...
fib(7) -> ...
fib(9) -> fib(7) -> ...
fib(8) -> ...
Note that fib(7) and fib(8) will be computed again even though their results are already known. The recursive calls grow exponentially. This is commonly covered in an introductory programming class as a poor example of using recursion.
Ben's code doesn't have that problem. It stores previously computed values in an array. The versions have subtly different characteristics. When calling fib(i). the depth of recursion is i / 2. Here are the calls made by fib(10):
fib(10) -> fib(8) -> fib(6) -> fib(4) -> fib(2) -> fib(0)
fib(1)
fib(3) -> fib(1)
fib(2)
fib(5) -> fib(3)
fib(4)
fib(7) -> fib(5)
fib(6)
fib(9) -> fib(7)
fib(8)
Also note that the number of recursive calls no longer grows exponentially since they are looked up in the memo array once known.
BTW, I am guessing that the % Short.MAX_VALUE is there just to make sure that the result can never be -1, which denotes a previously unknown result. Again, the focus is not on computing Fibonacci numbers, but on studying recursive call patterns.
The depth of recursion with fib2(i) is higher, namely i - 1, as you can see from this chain of calls:
fib2(10) -> fib2(9) -> fib2(8) -> fib2(7) -> ... -> fib(1)
Ben expected fib2 to conk out at some stack depth where fib still succeeds. But the order of the calls shouldn't matter. Yet it does:
fib: stack overflow at 20000 fib2: stack overflow at 20000 ====> reversing the order fib2: stack overflow at 20000 fib: 11628
That was his question. Why does the second call to fib succeed?
First off, I added a counter for the stack depth. That gave even more confusing results.
fib: stack overflow at 20000 maxDepth: 7744 fib2: stack overflow at 20000 maxDepth: 7441 ====> reversing the order fib2: stack overflow at 20000 maxDepth: 6558 fib: 11628 maxDepth: 10000
Why would the stack first get shorter and then long enough to make fib(20000) complete?
It almost looks like the stack size can adapt. I could find very little information about how the JVM stack is actually implemented. The JVM spec §2.5.2 is very vague: Because the Java Virtual Machine stack is never manipulated directly except to push and pop frames, frames may be heap allocated. The memory for a Java Virtual Machine stack does not need to be contiguous... This specification permits Java Virtual Machine stacks either to be of a fixed size or to dynamically expand and contract as required by the computation.
I experimented with the -Xss flag that sets the stack size. It influenced the size of the stack, but the strange behavior was still the same.
I found an article Stack Overflow handling in HotSpot JVM by Andrei Pangin that seemed interesting but unrelated. It talks about native calls and a “guard zone”.
The only other article that I ran across was On Stack Replacement in HotSpot JVM by Stanley Guan, published under the pseudonym of “XML and More”. It had some log records in XML, and my eyes glazed over. This was a mistake. It contained the seed to the actual explanation.

In desperation, I asked Heinz (“Hercule”) Kabutz. He sent me the program back with a simple change in main and the terse comment “run it several times and the mystery goes away ...”
public static void main(String[] args) {
int m = args.length < 1 ? 10 : Integer.parseInt(args[0]);
int n = args.length < 2 ? 20_000 : Integer.parseInt(args[1]);
for (int i = 0; i < m; i++) {
doFib(n);
doFib2(n);
System.out.println("====> reversing the order");
doFib2(n);
doFib(n);
System.out.println();
}
}
Sure enough, after a few iterations, the result becomes regular.
fib: stack overflow at 20000 maxDepth: 7737 fib2: stack overflow at 20000 maxDepth: 7480 ====> reversing the order fib2: stack overflow at 20000 maxDepth: 6558 fib: 11628 maxDepth: 10000 fib: stack overflow at 20000 maxDepth: 7378 fib2: 11628 maxDepth: 19999 ====> reversing the order fib2: stack overflow at 20000 maxDepth: 7232 fib: 11628 maxDepth: 10000 fib: 11628 maxDepth: 10000 fib2: stack overflow at 20000 maxDepth: 6558 ====> reversing the order fib2: stack overflow at 20000 maxDepth: 6558 fib: 11628 maxDepth: 10000 fib: 11628 maxDepth: 10000 fib2: stack overflow at 20000 maxDepth: 6558 ====> reversing the order fib2: 11628 maxDepth: 19999 fib: 11628 maxDepth: 10000 fib: 11628 maxDepth: 10000 fib2: 11628 maxDepth: 19999 ====> reversing the order fib2: 11628 maxDepth: 19999 fib: 11628 maxDepth: 10000 fib: 11628 maxDepth: 10000 fib2: 11628 maxDepth: 19999 ====> reversing the order fib2: 11628 maxDepth: 19999 fib: 11628 maxDepth: 10000 fib: 11628 maxDepth: 10000 fib2: 11628 maxDepth: 19999 ====> reversing the order fib2: 11628 maxDepth: 19999 fib: 11628 maxDepth: 10000 ...
Apparently the behavior becomes stable once the just-in-time compiler kicks in. The compiled instructions run just as expected. With larger values of n, calls to fib2(n) overflows the stack, but also without surprises (after a few initial confusing iterations).
To see when the JIT kicks in, run the program with
java -XX:+UnlockDiagnosticVMOptions "-XX:CompileCommand=print StackOverflowMystery::fib*" \ StackOverflowMystery 10 30000
On Ubuntu, I had to install libhsdis0-fcml. This detailed article shows you how to build the helper library on other platforms, and it goes into great detail about the disassembly process.
There are actually two levels of compilation, called C1 and C2. More details here.
You can turn off both levels, leaving the code to run under the virtual machine without Hotspot:
java -XX:+UnlockDiagnosticVMOptions -XX:TieredStopAtLevel=0 \ StackOverflowMystery 10 30000
Then the results are completely uniform again. The virtual machine does not magically grow the stack. (Thanks to this article for pointing out how to use the TieredStopAtLevel flag.)
The problem that Ben observed is a simple consequence of just-in-time compilation. Of course, the JIT doesn't neatly proceed after a top-level call to fib or fib2 has completed. Somewhere in the recursive call sequence, the JIT kicks in (twice). When the compiled call replaces the virtual machine call or C1 call, the stack contains a mixture of C2, C1, and virtual machine frames, which will have different sizes, as shown in this figure from Andrei Pangin's article:
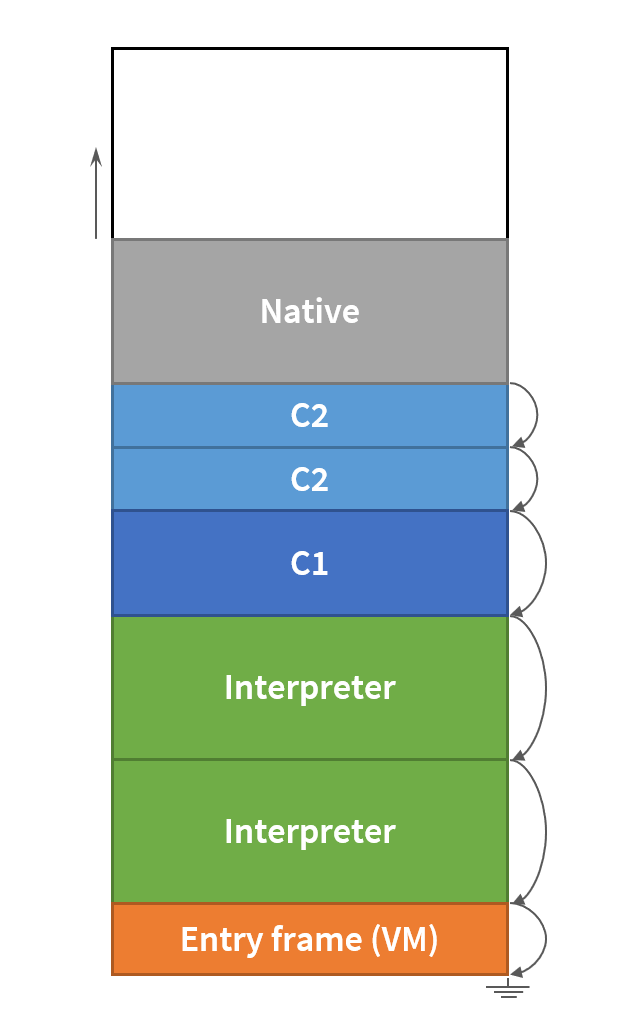
With such a mixture, it is hard to predict when exactly the stack overflows. Once all code is at C2, the behavior is uniform.
sort makes a native call, and no Python code can compete with that, O(n) or not. Is that tragic? If you want a teaching environment with a clear and consistent execution model, and no tragedy, consider either C or Scheme.StackOverflowMystery has no surprises, is faster and uses less memory.
Comments powered by Talkyard.