Users of one of my textbooks asked for a section on red-black trees. That makes sense—just lecturing about binary search trees leaves the nagging doubt what happens when a tree becomes unbalanced. Unhappily, the standard algorithms are a mess of fiddly special cases. Here is a simpler way of doing it, modifying the presentation by Chris Okasaki and Matt Might.
A red-black tree is a binary search tree with the following additional properties:
null have the same number of
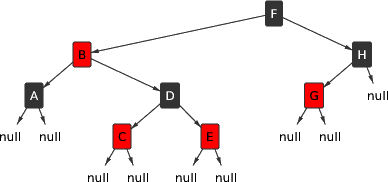
black nodes. I call this the “equal exit cost” rule.Here is one:
Of course, the nodes aren't actually colored. Each node simply has a flag to indicate whether it is considered red or black. (The choice of these colors is traditional; one could have equally well used some other attributes. Perhaps, in an alternate universe, students learn about chocolate-vanilla trees.)
Instead of the colors, I find it more useful to consider each node to be a
toll booth. As you travel from the root to one of the null
references (an exit), you have to pay $1 at each black toll booth, but the red
toll booths are free. The “equal exit cost” rule says that the cost of the
trip is the same, no matter which exit you choose.
The nulls turn out to be a bit troublesome, and many authors
replace them by dummy black leaves. Then all nodes either have two children or
are one of those dummy leaves. I didn't want dummy leaves—they are bound to
be confusing for beginning students. (This
stackoverflow user doesn't like them either).
I looked at several textbooks. The most concise descriptions reduce red-black trees to 2-4 trees, which is nice in an algorithms course, but it wasn't an option for me. Others use dummy leaves. The remaining ones present a mess of fiddly special cases. Working through them made me lose the will to live.
I was about to give up when a Google search pointed me to Lyn Turbak's lecture notes, and I gasped when I saw this:

The figure is attributed to Chris Okasaki, Purely Functional Data Structures, Cambridge University Press, 1998. I've got to get a copy.
This is brilliant. You insert a node in the usual way and color it red. If its parent is also red, reorganize as per the image. The red node goes one step further to the root. Repeat if necessary. If the red node arrives at the root, color it black.
Why does it work? The transformation doesn't change the cost of traveling through the nodes—it's $1 before and after. And changing the root from red to black—if it comes to that— just adds $1 to the cost of every trip.
I kept googling for a similar simplification of removal, and I found this excellent article by Matt Might. Unfortunately, it uses dummy nodes. But it wasn't that hard to reformulate his approach without them. Here goes.
As with insertion, first use the standard removal algorithm for binary search trees. Note that in that algorithm, the removed node has at most one child. We never remove a node with two children; instead, we fill it with the value of another node with at most one child, then we remove the other one.
Two cases are easy. First, if the node to be removed is red, there is no problem with the removal—the resulting tree is still a red-black tree.
Next, assume that the node to be removed has a child. Because of the “equal exit cost” rule, the child must be red. Simply remove the parent and color the child black.

The troublesome case is the removal of a black leaf. We can't just remove it
because the exit cost to the null replacing it would be too low.
Instead, we'll first turn it into a red node. (This is where I changed Matt's
algorithm. I transform first, then do the safe removal. That way, I need not
worry about nulls or dummy leaves.)
There are six possible positions for the black leaf X that should be removed. (Note that a black leaf must always have a sibling, and you can't have a red parent and a red sibling.)
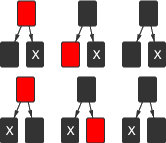
To turn a black node into a red one, temporarily “bubble up” the costs, raising the cost of the parent by $1 and lowering the cost of the children by $1.

Clearly, “bubbling up” leaves all path costs unchanged.
In the first column of the 6 cases above, bubbling up works perfectly—it simply turns the red node into a black one and the black ones into red ones. One of the red ones is removed. The other may cause a double-red violation with one of its children, in which case we fix it.
But in the other cases, a new problem arises. We get nodes with prices of 2 or -1, which Matt calls double-black and negative-red. In the toll booth analogy, a double-black node costs $2, and you get a dollar every time you pass through a negative-red one. Of course, these are not valid nodes in a red-black tree, and we need to eliminate them.
A negative-red node is always a child of a double-black node, and the pair can be eliminated by the transformation shown below (or its mirror image).

Sometimes, the creation of a double-black node also causes a double-red violation below. We can fix the double-red violation by generalizing Okasaki's transform. The gray node can have any cost, which is reduced by $1.

It is easy to check that both transformations preserve all travel costs.
Sometimes, neither of the two transformations applies, and then we need to “bubble up” again, which pushes the double-black node closer to the root.

If the double-black node reaches the root, we can replace it with a regular black node.
That's it. Here is an implementation in Java.